Due diligence technique : les 12 points que nous auditons systématiquement
Quand un fonds d’investissement ou un acquéreur s’apprête à s’engager avec une entreprise tech, la due diligence technique est le moment où l’on vérifie si le produit peut tenir la promesse commerciale qu’on lui attribue.
On peut imaginer naïvement que l’exercice consiste à regarder le code source et à chercher de la dette technique. C’est une partie du travail, mais c’est loin d’être suffisant. Une plateforme peut avoir une bonne architecture, une stack moderne, des performances excellentes et pour autant rester fragile parce qu’une seule personne concentre les accès, la connaissance et la capacité d’intervention en production.
Une due diligence ne cherche donc pas à distribuer des bons et des mauvais points. Elle cherche à comprendre le niveau de maturité du produit sur toutes les dimensions qui conditionnent sa pérennité : le fonctionnel, l’architecture, l’infrastructure, la sécurité, l’organisation, l’exploitation, la documentation, les dépendances humaines. La maturité technique n’est jamais monolithique. Une entreprise peut être avancée sur son architecture et émergente sur son organisation. Elle peut être excellente sur ses performances et fragile sur sa gestion des accès. Elle peut avoir de bons outils de monitoring, mais trop peu de personnes capables d’agir quand l’alerte tombe.
Chez Dernier Cri, nous avons progressivement stabilisé une grille de 12 points qui permet de poser un diagnostic factuel, utile et actionnable. L’objectif n’est pas de trouver la perfection. Elle n’existe pas. L’objectif est de faire apparaître les risques réels, de mesurer leur gravité, et de donner aux décideurs une base solide pour arbitrer.
Les 12 points que nous auditons
1. Le fonctionnel et la criticité métier
Avant de regarder la technique, on doit comprendre ce que fait le produit.
Quelles sont les fonctionnalités essentielles ? Quels usages sont réellement critiques ? Qu’est-ce qui relève du confort, et qu’est-ce qui met l’activité du client en danger si cela tombe ?
Cette étape paraît évidente, mais elle est indispensable. Une lenteur de deux secondes n’a pas le même impact sur un back-office consulté une fois par semaine que sur une application utilisée en plein rush opérationnel. Le niveau d’exigence technique dépend toujours du contexte métier.
2. Les utilisateurs, les volumes et le profil de charge
Combien d’utilisateurs ? Combien de clients ? Combien d’organisations ? Quelle volumétrie de données ? La charge est-elle constante, saisonnière, quotidienne, imprévisible ?
On cherche ici à comprendre le rythme réel de la plateforme. Une charge prévisible est une bonne nouvelle : elle peut être anticipée. Un pic quotidien connu, par exemple au moment d’une synchronisation de données, n’est pas un problème en soi si l’architecture est dimensionnée pour l’encaisser.
Les chiffres bruts ne suffisent pas. Dire qu’une plateforme peut gérer plusieurs milliers de requêtes par seconde est intéressant. Comprendre dans quelles conditions, avec quelles marges, et sur quels parcours l’est beaucoup plus.
3. L’architecture générale
On commence par prendre de la hauteur : quel est le schéma d’architecture de la plateforme ?
C’est étonnant de constater que beaucoup d’équipes n’ont pas cette vue d’ensemble à jour. Elles connaissent chaque morceau, mais peinent à représenter le système complet : frontends, backends, services tiers, bases de données, jobs queues, CDN, authentification, APIs, applications mobiles.
Une bonne architecture n’est pas forcément l’architecture la plus sophistiquée. C’est celle qui correspond à la taille de l’équipe, aux contraintes du produit et aux ambitions de la roadmap.
Pour une petite équipe, un monolithe bien tenu est toujours supérieur à une constellation de microservices mal maîtrisés. À l’inverse, une architecture orientée services peut être pertinente si elle isole clairement des domaines techniques ou métier, sans créer une complexité artificielle.
4. La stack technique et les dépendances structurantes
On audite ensuite les choix technologiques : langages, frameworks, bases de données, solutions cloud, librairies critiques, outils mobiles, dépendances externes.
La question n’est pas de savoir si la stack est à la mode. La question est de savoir si elle est maintenue, comprise par l’équipe, adaptée au produit, et suffisamment standard pour ne pas enfermer l’entreprise.
Une technologie mature, documentée, avec un écosystème large, est souvent un excellent choix. Le risque vient plutôt des dépendances exotiques, des versions obsolètes, des migrations bloquées, ou des composants que plus personne dans l’équipe ne sait faire évoluer.
Depuis peu, l’IA ajoute une nouvelle couche de complexité et de dépendances : APIs de modèles, bases vectorielles. Ces briques évoluent vite, coûtent cher et créent un vendor lock-in d’un genre nouveau. On audite la même chose que pour le reste de la stack : est-ce maîtrisé, est-ce substituable, est-ce que l’équipe comprend ce qu’elle utilise ?
5. La qualité du code et la dette technique
La revue de code, les conventions, les linters, l’analyse statique, la lisibilité des modules, la séparation des responsabilités : tout cela compte.
Mais il faut éviter une lecture esthétique du code. Un audit ne cherche pas à savoir si le code correspond aux préférences personnelles de l’auditeur. Il cherche à savoir si le code peut être compris, modifié et maintenu par l’équipe en place.
Avoir de la dette technique n’est pas un drame car elle existe dans tous les produits tech vivants. Le vrai sujet est de savoir si elle est connue, contenue et quelle est la stratégie pour l’adresser.
L’usage croissant d’outils de génération de code par IA (Copilot, Cursor, etc.) rend cette question encore plus aiguë. Du code peut être produit très vite sans être compris par celui qui l’a accepté. En audit, on regarde si l’équipe est capable de lire, expliquer et modifier ce qu’elle a livré, quelle qu’en soit l’origine.
6. Les tests, la CI/CD et les déploiements
Les tests automatisés ne sont pas une ligne à cocher. Ils disent quelque chose de la capacité de l’équipe à faire évoluer le produit sans peur.
On regarde les tests unitaires, les tests d’intégration, les tests d’API, les tests end-to-end, mais aussi la façon dont ils sont exécutés : localement, dans la CI, avant déploiement, après déploiement.
L’absence totale de tests end-to-end n’est pas toujours bloquante, mais elle devient vite un sujet dès que la plateforme porte des parcours critiques. À un certain niveau de maturité, on ne peut plus uniquement compter sur la vigilance humaine pour sécuriser les mises en production.
7. L’infrastructure et les environnements
Cloud, PaaS, Kubernetes, machines virtuelles, serverless, conteneurs : les choix sont nombreux, mais le sujet reste le même. L’infrastructure est-elle reproductible, documentée, observable, maîtrisée ?
L’usage d’outils comme Terraform est souvent un bon signal. Il montre que l’infrastructure n’est pas seulement configurée à la main dans une console web, mais pensée comme un actif que l’on peut versionner et reconstruire.
On regarde aussi les environnements : production, staging, développement. Sont-ils cohérents ? Qui y a accès ? Que teste-t-on vraiment avant de déployer ? Peut-on restaurer rapidement un environnement en cas de problème ?
Se pose aussi la question des coûts. Il y a une différence énorme entre des hébergeurs cloud tels que AWS ou GCP et d’autres moins proéminents tels Scalingo ou Hetzner. Les plateformes qui intègrent des fonctionnalités d’IA ajoutent à cela des coûts d’inférence souvent difficiles à prévoir : consommation de tokens, appels API facturés à l’usage. Comme pour les points précédents tout est question de mesure : une infrastructure doit avoir un coût raisonnable et prévisible par rapport au service qu’elle rend.
8. La sécurité, les secrets et la conformité
La sécurité d’une plateforme commence souvent par des choses simples : gestion des accès, séparation des rôles, stockage des secrets, authentification, chiffrement, sauvegardes, dépendances à jour.
On audite aussi la conformité : données personnelles collectées, procédures d’anonymisation, RGPD, politique de conservation, exposition des données entre clients dans les architectures multi-tenant.
Lorsque la plateforme utilise des services d’IA, la question de la donnée prend une dimension supplémentaire : quelles données transitent vers des fournisseurs tiers ? Les prompts contiennent-ils des données personnelles ou sensibles ? Les conditions d’utilisation des modèles sont-elles compatibles avec les engagements pris envers les clients ?
Les failles évidentes sont souvent les plus coûteuses.
9. L’observabilité, les logs et les alertes
Logs structurés, suivi des erreurs, métriques système, métriques applicatives, alertes, tableaux de bord : l’observabilité permet de comprendre ce qui se passe quand la plateforme se comporte mal.
Mais les outils ne suffisent pas. Trop d’alertes rend l’alerting inexploitable. A l’inverse, des systèmes de monitoring jamais consultés ne servent à rien. Une alerte utile est une alerte que quelqu’un peut comprendre, prioriser et actionner. On peut avoir CloudWatch, Sentry, New Relic, des dashboards propres et des alertes nombreuses, tout en restant fragile si une seule personne sait quoi faire quand un incident se produit.
10. L’exploitation, le support et la gestion des incidents
Qui traite les bugs ? Qui priorise les anomalies ? Quels sont les délais de résolution ? Existe-t-il une page de statut ? Comment les incidents sont-ils documentés ? Y a-t-il des post-mortems ? Qui peut intervenir en production ?
La roadmap avance moins vite non pas parce que l’équipe manque d’idées, mais parce qu’elle passe son énergie à tenir l’existant.
11. L’équipe, l’organisation et le bus factor
Une plateforme peut être techniquement saine et organisationnellement fragile. Si une seule personne concentre la direction technique, la connaissance historique, les accès de production, les décisions produit, les interventions d’urgence et la relation aux prestataires, on n’a pas seulement un sujet RH. On a un risque produit.
Le bus factor n’est pas une critique des petites équipes. Dans une startup ou une PME, il est normal que certaines personnes portent beaucoup. Mais à partir d’un certain niveau d’engagement client, il faut organiser le relais : documentation, droits d’accès, procédures d’incident, montée en compétence, répartition des responsabilités. Une équipe fragile fragilise tout le reste.
De même, lorsqu’une équipe est en place, la manière dont elle approche le build est important : fonctionne-t-elle via des sprints ? comment interagit-elle avec le produit ? comment la roadmap est absorbée ?
12. La documentation, la propriété intellectuelle et l’interopérabilité
La documentation dit beaucoup de la maturité d’une organisation. Elle permet d’onboarder, de transmettre, de diagnostiquer, de reprendre un sujet après six mois, de réduire la dépendance aux individus.
On audite aussi la propriété intellectuelle : qui a produit le code ? Y a-t-il eu des prestataires ? Les contrats sont-ils clairs ? Les comptes critiques appartiennent-ils bien à l’entreprise ? Les stores mobiles, le cloud, les domaines, les outils de déploiement sont-ils détenus par les bonnes entités ?
Enfin, on regarde l’interopérabilité. Une plateforme API-centrique, bien documentée, capable de s’intégrer à d’autres systèmes, aura souvent plus de valeur et plus de marge d’évolution qu’un produit fermé sur lui-même.
Une grille de maturité plutôt qu’un verdict
Pour chacun de ces points, nous préférons raisonner en niveaux de maturité :
- émergent : le sujet existe, mais il repose encore beaucoup sur l’informel ;
- fonctionnel : les pratiques de base sont en place ;
- intermédiaire : les fondamentaux sont solides, mais certaines zones restent perfectibles ;
- avancé : le sujet est bien maîtrisé et documenté ;
- optimal : le niveau est excellent au regard du contexte de l’entreprise.
Cette approche évite les conclusions paresseuses. Une plateforme n’est presque jamais bonne ou mauvaise dans son ensemble. Elle est mature sur certains axes, fragile sur d’autres. C’est précisément ce que l’on cherche à faire apparaître.
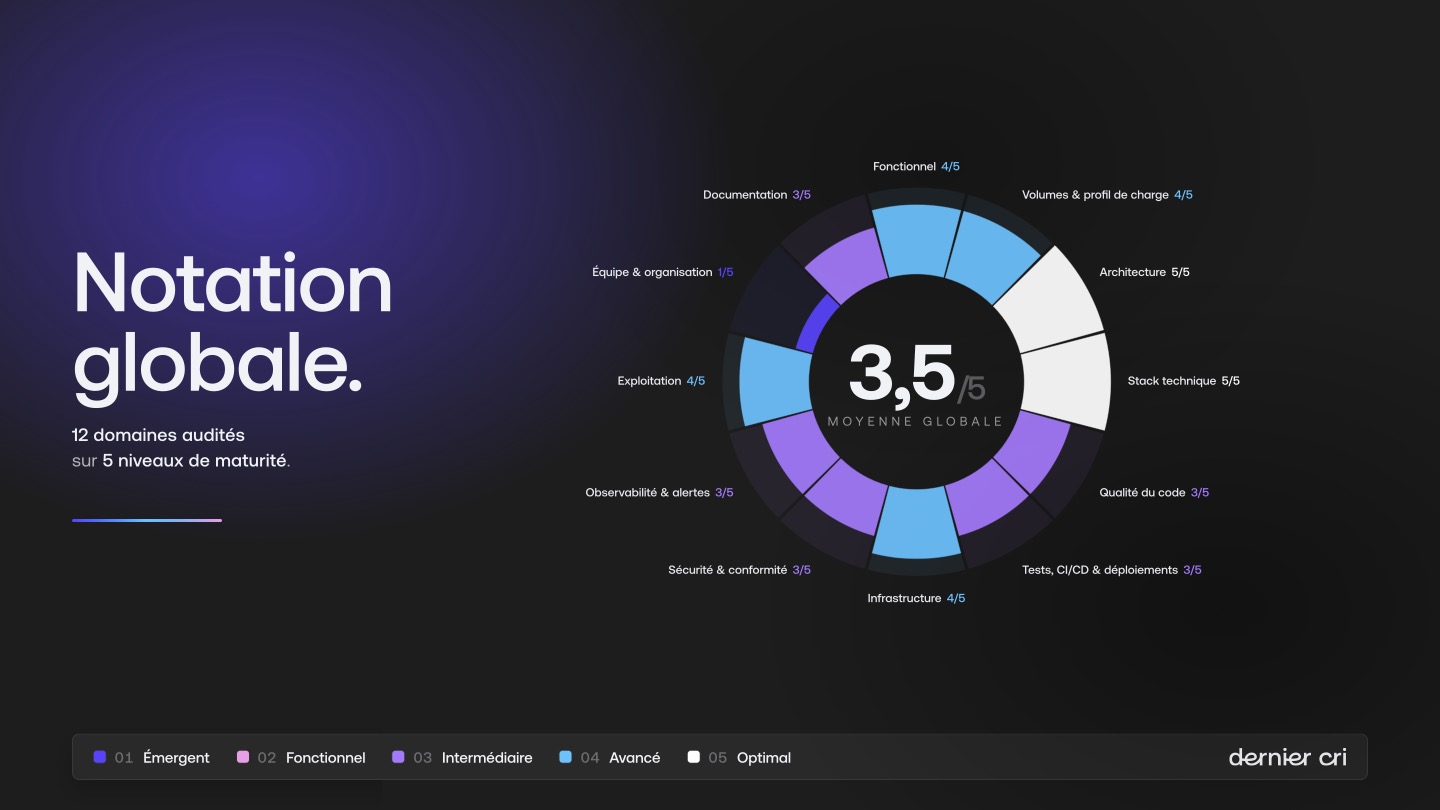
Une due diligence réussie est une approche holistique
Une due diligence technique bien menée ne sert pas à trouver la perfection. Elle sert à quantifier les risques, estimer les coûts de remédiation et donner aux décideurs les éléments concrets pour négocier, investir ou s’engager en connaissance de cause.
Le risque principal n’est pas toujours là où on l’attend. Parfois, il est dans une vieille version de framework. Parfois, dans une absence de tests. Parfois, dans une infrastructure bricolée. Et très souvent, il est dans les dépendances humaines : une personne qui sait tout, qui possède tout, qui débloque tout. La valeur d’un audit est là : transformer une impression floue, du type “le code a l’air propre”, en une lecture factuelle de la pérennité du produit.
On n’a pas besoin d’une plateforme parfaite pour investir, acquérir ou déployer. On a besoin de savoir clairement ce qui est solide, ce qui est fragile, et ce qu’il faudra renforcer pour passer à l’étape suivante.

Questions fréquentes
Qu'est-ce qu'une due diligence technique ?
C'est l'examen mené quand un fonds d'investissement ou un acquéreur s'apprête à s'engager avec une entreprise tech, pour vérifier si le produit peut tenir la promesse commerciale qu'on lui attribue. Elle ne cherche pas à distribuer des bons et des mauvais points : elle mesure le niveau de maturité réel du produit sur toutes les dimensions qui conditionnent sa pérennité — fonctionnel, architecture, infrastructure, sécurité, organisation, exploitation, documentation et dépendances humaines.
Que vérifie-t-on lors d'une due diligence technique ?
Chez Dernier Cri, nous auditons douze points : le fonctionnel et la criticité métier, les volumes et le profil de charge, l'architecture générale, la stack et ses dépendances structurantes, la qualité du code et la dette technique, les tests et la CI/CD, l'infrastructure et les environnements, la sécurité et la conformité, l'observabilité, l'exploitation et la gestion des incidents, l'équipe et le bus factor, enfin la documentation, la propriété intellectuelle et l'interopérabilité. Aucun de ces points ne suffit seul : c'est leur combinaison qui révèle la pérennité du produit.
La due diligence technique se limite-t-elle à l'audit du code ?
Non, et c'est l'erreur la plus courante. Regarder le code source et y chercher de la dette technique n'est qu'une partie du travail. Une plateforme peut avoir une bonne architecture, une stack moderne et d'excellentes performances tout en restant fragile parce qu'une seule personne concentre les accès, la connaissance et la capacité d'intervention en production. Le vrai risque se loge souvent ailleurs que dans le code.
Qu'est-ce que le bus factor et pourquoi est-il critique ?
Le bus factor mesure la dépendance d'un produit à un très petit nombre de personnes. Si une seule concentre la direction technique, la connaissance historique, les accès de production et les interventions d'urgence, ce n'est plus seulement un sujet RH : c'est un risque produit. Ce n'est pas une critique des petites équipes — il est normal que certaines personnes portent beaucoup — mais à partir d'un certain niveau d'engagement client, il faut organiser le relais : documentation, droits d'accès, procédures d'incident, montée en compétence et répartition des responsabilités.
Une due diligence technique sert-elle à trouver un produit parfait ?
Non. La perfection n'existe pas, et on n'en a pas besoin pour investir, acquérir ou déployer. L'objectif est de faire apparaître les risques réels, de mesurer leur gravité et d'estimer les coûts de remédiation. Plutôt qu'un verdict binaire, nous raisonnons en niveaux de maturité — émergent, fonctionnel, intermédiaire, avancé, optimal — car une plateforme est presque toujours mature sur certains axes et fragile sur d'autres. Ce qu'on veut, c'est savoir clairement ce qui est solide, ce qui est fragile, et ce qu'il faudra renforcer pour passer à l'étape suivante.
Vous avez un
produit en tête ?
Construisons-le ensemble.